混淆矩阵:
也称为误差矩阵,是一种特定的表格布局,允许可视化算法的性能,通常是监督学习的算法(在无监督学习通常称为匹配矩阵)。矩阵的每一行代表预测类中的实例,而每列代表实际类中的实例(反之亦然)。从字面理解:看出系统是否混淆了两个类(即通常将一个类错误标记为另一个类)(多类可以合并为二分类)。
一级评价指标:
由四个基础指标构成:TP、FN、FP、TN
① 真实值是positive,模型认为是positive的数量(True Positive=TP)
② 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error)
③ 真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error)
④ 真实值是negative,模型认为是negative的数量(True Negative=TN)
一级评价指标混淆矩阵图例:
.png)
二级评价指标:
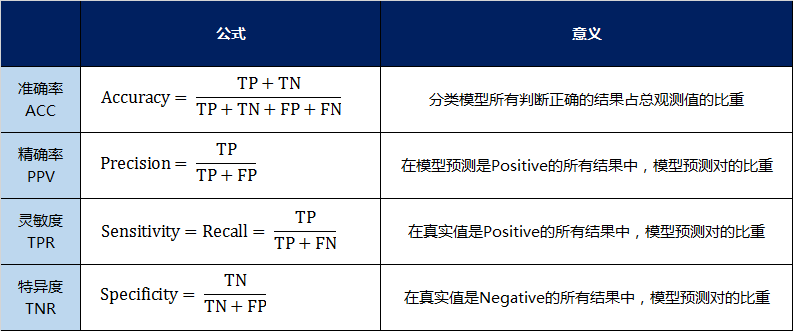
准确率(Accuracy):ACC
精确率(Precision):PPV
灵敏度(Sensitivity)=召回率(Recall)=命中率=真实阳性率:TPR
特异度(Specificity):TNR
(更多名词可查看维基百科)
三级评价指标:
F1 Score:
其中,P代表Precision,R代表Recall。F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
MCC 马修斯相关系数:
衡量不平衡数据集的指标比较好。
ROC曲线:
ROC曲线的横坐标为false positive rate(FPR),纵坐标为 true positive rate(TPR) 。当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
PRC曲线:
在正负样本分布得极不均匀(highly skewed datasets)的情况下,PRC比ROC能更有效地反应分类器的好坏。
实列理解:
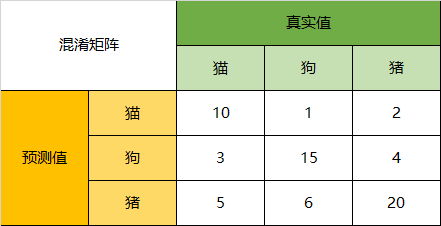
该图表示的是模型预测动物的预测数据图。通过该混淆矩阵,可以得到以下结论:
Accuracy:
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
下面以猫为例,将上面的图合并为二分类问题,求出二级评价指标与三级评价指标:
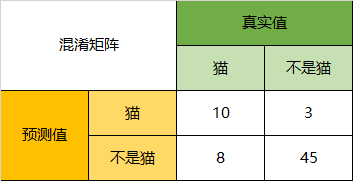
Precision:
以猫为例,66只动物里有13只是猫,其中这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall:
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。这5只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
Specificity:
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。虽然在45只动物里,模型依然认为错判了6只猪与4只狗,但是从猫的角度而言,模型的判断是没有错的。
F1-Score:
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
参考链接:
维基百科:https://en.wikipedia.org/wiki/Confusion_matrix
CSDN:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839

